

Convergence of functions require more compute power from processors and SoCs. For many decades Moore’s law helpfully delivered the performance gains necessary without the need for significant design changes. However, that source of steady performance gains is slowing down.
Moore’s Law which states that computer power doubles every two years at the same cost has been fading since a long time. Those two years are drastically reducing to the point that there is a set of people who still believe in it and the other set of people who defend it.
How It All Began?

It all started, when Intel released the 4004 microprocessor with 2,300 transistors. The gap between each transistor was 10,000 nanometers in 1971. After 44 years that gap has been reduced to 14 nanometers, accomodating trillions of transistors on a single chip.
This has been possible due to the unique quality in small transistors of being turned on and off with lesser power but greater speeds. However another catch is that, technology has already reached a point that one can’t add more transistor to the current design. Various semiconductor companies have started searching and implementing different techniques to increase the speed and stability of the existing design.
The mobile application processor on your $150 smart phone may already have cost the chip company upwards of $100 million USD for design. The cost of designing complex multi-core server chips is a different story altogether. These costs assume a certain static base design with minor changes in every revision. If fundamental design changes becomes a necessity due to the slowing Moore’s law, design costs for complex SoCs may start growing exponentially.
Fortunately, companies like Tensilica (now part of Cadence), Sankhya Technologies, design teams at ARM and a bunch of other design automation companies have been working to create design flows that allow small design teams to create more complex designs faster. System design automation platforms, that allow high level abstractions to be modelled and used to drive system design are already available in the market today.
The growing complexity of systems is forcing technology leaders from across the semiconductor ecosystem to collaborate. No wonder there is a lot of M&A activity – the recent acquisition of Altera by Intel is a case in point. TSMC partnering with ARM for 7 nm designs is an indication of the kind of global alliances that are in the making.
Chip designers around the world now search for a future where performance gains come from not just better semiconductor fabrication technologies – but also from improved processor and SoC designs.
This situation may present India with yet another opportunity to leapfrog global competition. Some vision and quick action by policy makers is key for grabbing that opportunity.
Breaking down of Moore’s Law, means innovation has certanly increased expectations. The current solutions however are still not enough for another breakthrough. More methods have to come into the mix for a better future. Current solutions along with some additions often lead to the best results. Let’s look at some of the solutions that could help.
Synthetic Manifold: Design Flow And System Elaboration
The Teraptor Synthetic IoT Platform offers tools and libraries to automatically synthesize a manifold system from its models. The synthetic manifold can be implemented as a distributed software grid, hardware (FPGA, ASIC) or as a virtual system that can be played on Teraptor Player – a system simulator. These tools take care of synthesizing the individual elements, the network and communication between elements.
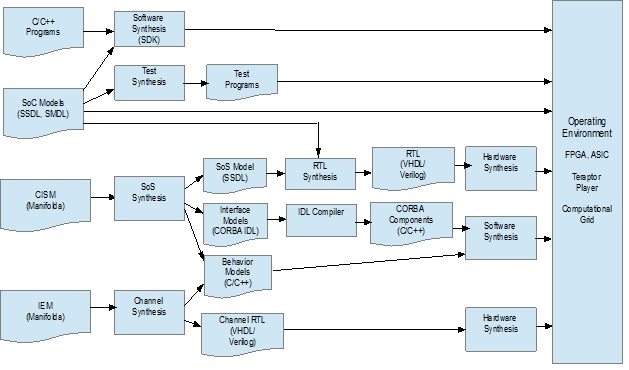
Fig.1 shows the complex intelligent system design flow using the SANKHYA Teraptor Synthetic IoT Platform. The top-level system architecture (Complex Intelligent System Models – CISM) and Intelligent Element Models (IEM) are specified using the Manifold.
These models are provided as input to the Teraptor system compiler to synthesize System Model (SSDL), Interface models (CORBA IDL) and behavior models (C/C++). These can be further synthesized into hardware description (FPGA, ASIC), distributed software grid (SANKHYA Infiniproc) or components for playing using Teraptor Player. The SANKHYA Infiniproc platform allows construction of data factory to process large amounts of data in real time. This finds application for example in high performance computing, financial trading and analysis.
The models of processor or SoC components of the system are described using SMDL and SSDL. These models can be realized as hardware or software as before. These models can also be provided to the Teraptor Verifier to generate processor test programs to verify the processor components.
The platform also includes Software Develop Kit to compile software programs to the target processor architecture.
For more related articles: click here





