

We all witness every day how incredibly Google enables us to access a specific piece of information. But do you know how Google is able to offer matching search results out of hundreds of millions of webpages available? Find out
Manuj Arora
Search engines serve users with the specific information they are looking for over the Web. These are highly potent tools that offer specific and fast search results to the users by providing information stored on other sites. They offer users high ease to access the Web. The users have to just type in the query regarding the information they are searching for and rest is the work of these search engines to provide the relevant results.
Among a number of search engines available over the Web, Google is the most dominant and the most widely used search engine.
Google search engine is owned by Google Inc. It was originally developed by Larry Page and Sergey Brin in 1997. Every day, over billions of Google hits for searches are reported over the world, which clearly exemplifies the universal popularity of this search engine.

The general appearance of Google home page is shown in Fig. 1. Google has a regular tendency to amaze its users. So quite often it stages unique logos at its home page to honour certain events.
How Google Search Engine works
There are hundreds of millions of webpages available over the Web, most of which are titled on the whim of their author. Let’s see how Google is able to offer incredible search results out of hundreds of millions of webpages available.
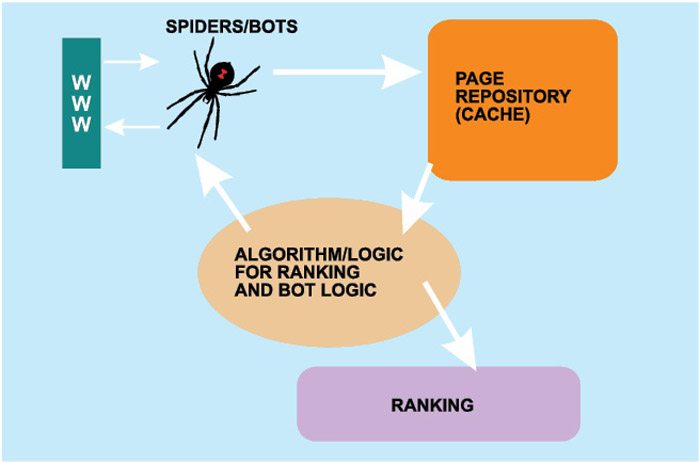
Google search engine employs Spider software or Web crawlers to search over the Web (Fig. 2).
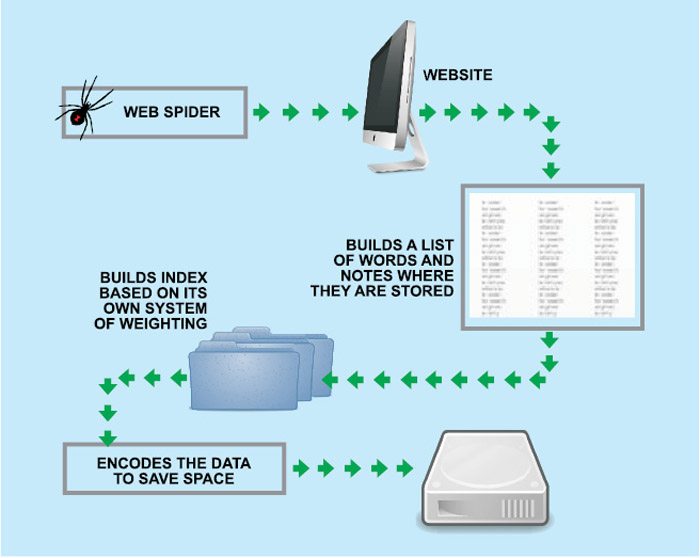
The spider software or Web crawler is an automated program that crawls over the Web for information stored on billions of websites and submits the pages to the search engine through links. Googlebot is the spider software that is used by Google search engine.
The search engine starts with a crawler module in which spiders/crawlers or googlebots are sent to the Web to crawl the websites. The spiders start by fetching a few webpages, then they follow the links on those pages and fetch the pages they point to, follow all the links on those pages and fetch the pages they link to, and so on.
There are billions of pages stored across thousands of machines. Spiders extract the data on webpages from websites and store it in a page repository. Then data is sent to an indexing module, which strips the contents from these pages and extracts key elements like title tag, description tag, data about images and internal links. Basically, the indexing module provides a really condensed summary of each webpage, like cliff notes. It then puts the data in a database referred to as index. All these activities go on all the time, regardless of whether a query is made for search or not.
When a query is made
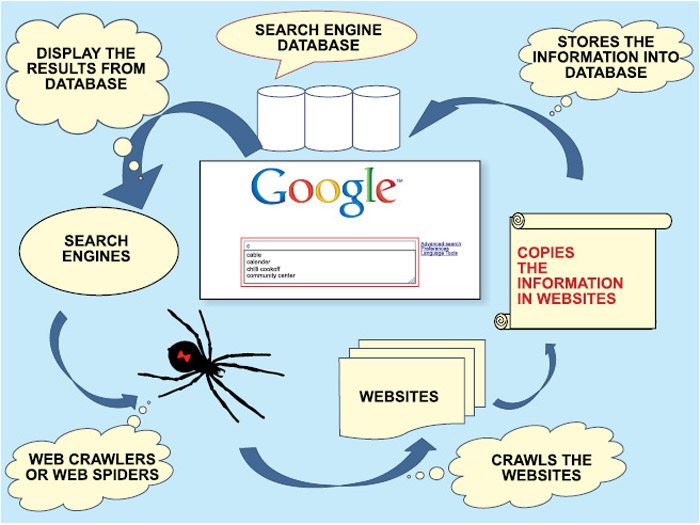
When the user types in a query in Google search box (Fig. 3), the query is broken down into a language that the search engine can understand. The query module extracts thousands and thousands of results back from databases/indices. On the results obtained, the ranking module applies a formula to rank the pages, presenting the user with the most relevant pages in the order of ranking.
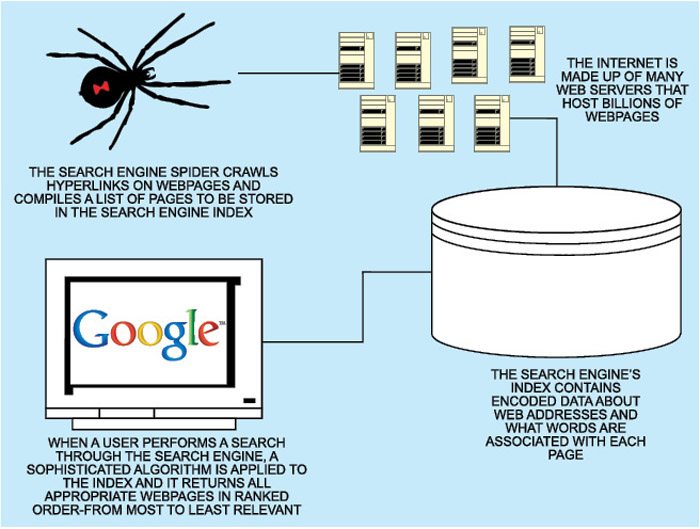
How Websites are ranked
Google employs Link based algorithm to determine the rank of results (Fig. 5). For this, the algorithm checks for link popularity (how many links the page has), page rank (how powerful the link is), link reputation (how is the quality of links—whether they are from high-ranking websites and whether the link text is relevant to the page subject) and many other factors in order to provide ranked results.
The results are presented to the user as per the ranking.
The author is a software engineer at a leading MNC





