



The new AI technique enhances 3D mapping for autonomous vehicles, promising improved navigation and safety by converting 2D images to 3D space.
Researchers at NC State University have developed a technique that could significantly improve the navigation capabilities of autonomous vehicles. This method enables artificial intelligence programs to map three-dimensional spaces more precisely using two-dimensional images.
Most autonomous vehicles utilise advanced AI programs known as vision transformers, which convert 2D images from multiple cameras into a 3D spatial representation surrounding the vehicle. Despite the variety of methods these AI programs use, there remains considerable potential for enhancement. The new technique developed by the team could significantly refine these programs across the board.

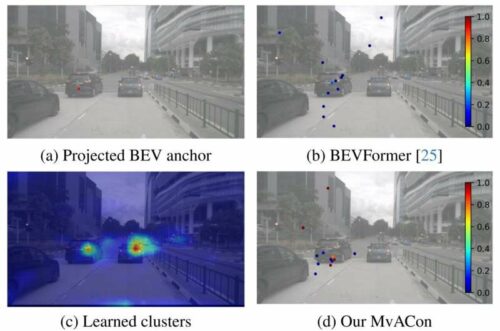
The research introduces Multi-View Attentive Contextualization (MvACon), a straightforward yet impactful method to enhance the conversion of 2D features into 3D representations for query-based multi-view 3D (MV3D) object detection. Despite significant advancements in the field, earlier methods have faced difficulties, such as fully utilising high-resolution 2D features in dense attention-based transformations due to high computational costs or failing to adequately anchor 3D queries to multi-scale 2D features in sparse attention-based transformations.
MvACon addresses these issues by implementing a representationally dense yet computationally efficient scheme for attentive feature contextualization. This approach operates independently of the specific 2D-to-3D feature transformation techniques used, making it a versatile solution for improving the accuracy and efficiency of MV3D object detection systems.
The technique acts as a plug-and-play supplement that can enhance existing vision transformer AIs used in autonomous vehicles. This enhancement allows the vision transformers to utilise the same camera data more effectively to map 3D spaces without requiring additional input.
The research team evaluated the effectiveness of MvACon with three top vision transformers available in the market, each using a set of six cameras to gather the 2D images they process. MvACon notably enhanced the performance of all three systems.
The researchers believe that the performance improvements were particularly notable in the areas of object detection as well as determining the speed and orientation of those objects.
Reference: Paper: Multi-View Attentive Contextualization for Multi-View 3D Object Detection
