

TarsosDSP as an example
In this article we will discuss a Java based real-time audio analysis and processing framework known as TarsosDSP.
The tool is counted as one among the few frameworks in Java ecosystem that provides both real-time feature extraction as well as synthesis. The framework consists of easily-extendable practical audio-processing algorithms. Owing to the educational goal of music information retrieval (MIR), these algorithms are made as simple and self-contained as possible using a straightforward pipeline.
Whether you are a student trying to understand the concepts of MIR or an experienced researcher working on music analysis, TarsosDSP is the ideal choice for you. The real-time feature extraction and synthesis capabilities make this software an ideal candidate for music education tools and music video games. Try out the latest release of the software version 2.2 that comes with this month’s DVD for EFY Plus.

Implementation in Java ecosystem
The framework, written in Java ecosystem, allows clean implementation of audio-processing algorithms. Compared to the ones written in C++, this Java based framework ensures better portability between various platforms.
 The automatic memory-management facilities are yet another advantage implementing the framework in Java. The Dalvik Java runtime allows running the algorithms unmodified on Android platform.
The automatic memory-management facilities are yet another advantage implementing the framework in Java. The Dalvik Java runtime allows running the algorithms unmodified on Android platform.
With the exception of the standard Java runtime, there are no other external dependencies. For real-time applications, the operating environment is optimised to provide a low-latency audio pipeline.
Simple processing pipeline
Another notable feature of this framework is its extremely simple processing pipeline. Limiting the input to a single-channel input makes the processing chain very straightforward. A multichannel audio input is automatically down-mixed to a single channel before it is taken to the processing pipeline.
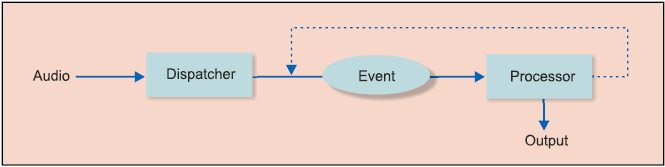
Input samples are chopped and arranged into samples in blocks of variable sizes having a defined overlap, with the help of AudioDispatcher. The blocks are then wrapped and encapsulated in an AudioEvent object having a pointer for timing and some auxiliary methods for computing the energy of the blocks.
AudioEvent is passed through a series of AudioProcessor objects by AudioDispatcher. The core of the algorithms such as pitch estimation or onset detection is carried out in AudioProcessor.

TarsosDSP and competing tools
There are a handful of tools available in the market that work on audio signals.
Essentia software is an open source C++ library that allows us to have real-time music analysis. CLAM tool allows us to have real-time music analysis as well as synthesis, and is based on C language.
Create Signal Library (Sizzle) and SndObj are more C++ based projects that allow users to have both audio analysis and synthesis in real-time.
Beads, JASS, JSyn and Minim are Java based projects that allow users to have real-time audio synthesis.
TarsosDSP is introduced as a single framework that could cater real-time music analysis and synthesis needs in Java—something that no other competing tools provide—as per the research conducted by the developers of the tool.
Although algorithms used in software like jAudio and YAAFE are more efficient due to the reuse of calculations for feature extraction, these are less readable compared to TarsosDSP.
Highly-optimised libraries such as SoundTouch are again less beneficial for beginners on account of low readability.
Main features implemented
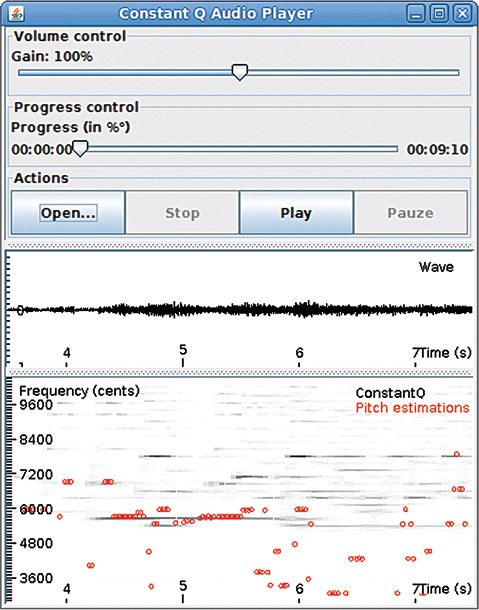
The tool was originally devised as a library for pitch estimation. Therefore you will find several pitch-estimating algorithms in this framework including YIN, McLeod Pitch Method (MPM), Average Magnitude Difference Function (AMDF) and an estimator based on dynamic wavelets.
There is a time-stretch algorithm using which the user can alter the speed of audio without changing the pitch.
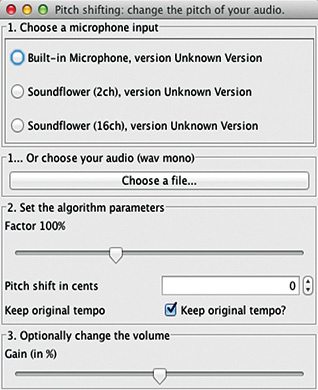
Alternatively, we also have a pitch-shifting algorithm that allows the user to change the pitch without changing the speed. A resampling algorithm with related software package is also included.
TarsosDSP consists of two onset detectors and several infinite impulse response (IIR) filters including low-pass, high-pass and band-pass filters. Audio effects like delay and flanger effect are also provided. In a flanger, two copies of the same signal are mixed, with one of these slightly delayed for not more than 20 milliseconds to produce a swirling effect.
Another important functionality of the tool is audio synthesis. We can find sine-wave and noise generator in the tool. A low-frequency oscillator is also incorporated for amplitude control. Spectrum-estimating algorithms based on fast Fourier transforms and other techniques are also available.
Lossy audio compression using Haar Wavelet Transform
Haar Wavelet Transform (HWT) is widely used in various image- and signal-processing applications. It could be effectively used in signal compression or for edge detection in images. Let us take a look at one such use case of HWT algorithm implemented in TarsosDSP.
HWT used for a simple Lossy audio compression consists of the following steps:





