



In a complex embedded system, a small bug may crash the whole system, or worse, put it into a dangerous operating mode. Bugs are not the only problem. A perfectly-designed-and-tested device on which a perfect code executes can still fail. A watchdog timer (WDT) is a safety mechanism that brings the system back to life when it crashes. For this reason, it must be well-designed and implemented for robust embedded system development.
A WDT is a hardware that contains a timing device and clock source. A timing device is a free-running timer, which is set to a certain value that gets decremented continuously. When the value reaches zero, a short pulse is generated by WDT circuitry that resets and restarts the system.

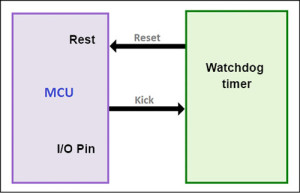
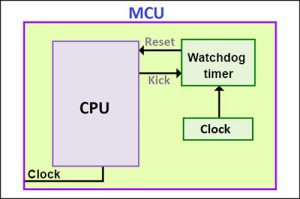
It is the application’s responsibility to reload WDT value each time before it reaches zero, else WDT circuitry will reset the system. Once reloaded, it will again start decrementing. In short, WDT constantly watches the execution of the code and resets the system if software is hung or no longer executing the correct sequence of the code. Reloading of WDT value by the software is called kicking the watchdog.
Watchdog based design considerations
1. The clock source for WDT must be separate, which means that it should not share the system clock. If the crystal stops under normal operation, say, in sleep mode, the watchdog will not work.
2. Once WDT initialisation is complete and WDT starts, the software should not be able to disable the watchdog or modify its control registers to stop a buggy code from accidentally disabling it. Some processors do have this locking feature.
3. After the watchdog resets, the system must come back to a known state under any condition.
4. The watchdog reset sequence must ensure that all connected peripherals are also brought back to a known state.
Types of watchdog timers
WDTs can be divided into two general categories: external WDT and internal WDT. Most microcontrollers have an internal WDT. Various chip vendors also provide external WDT chips.
An external WDT has a physical reset pin for the processor. An I/O pin of the processor is used to kick the watchdog.
Non-watchdog based design problems
In 1994, a deep-space probe, the Clementine, was launched to make observations of the Moon and a large asteroid, 1620 Geo graphos. After months of operation, a software exception caused a control thruster to fire for 11 minutes, which depleted most of the remaining fuel and caused the probe to rotate at 80rpm. Control was eventually regained, but it was too late to successfully complete the mission.
There can always be a bug present in the embedded system design, even if the code is designed very carefully. If we test our device in a heavy-electrical, noisy environment, a high-voltage spike may corrupt the program counter or stack pointer. Cosmic rays are also evil for the digital system and can alter the processor’s register bits.
Software can cause the system to hang indefinitely, in case of an infinite loop, buffer overflow or deadlocks. In a small embedded device, it is easy to find the exact root cause of the bug, but not so in a complex embedded system. However, by using a watchdog, we can ensure that the system will not hang indefinitely.
Hence, the system software in any situation should not hang infinitely. A general solution, in case it does hang, is to reset the system, and this is where watchdogs in embedded systems come in handy.
