


We all use electronic systems in our day-to-day life. Many times we have seen that when systems fail, things get difficult. Consequences can be serious if failure happens in a critical function. For example, imagine you are travelling in an aircraft and the main controller controlling the aircraft fails. When applications that involve safety of our lives fail, how we handle them becomes critical.
Reliable systems are designed based on the data collected about the failure of the components used in the system. Reliability is a figure that can be predicted based on certain parameters for every system. Essentially, reliability is just a predicted number based on probability and does not let the system work in case of failure.
A fault-tolerant (FT) system, on the other hand, will work even if there is a single or multiple faults (based on design) in the system.

Another critical aspect that we need to remember is how fault-tolerance is implemented. Let us take the example of a telephone exchange. If there is a problem in the phone line or line interface in the exchange, the fault can be rectified only when we replace the faulty part with a good one. However, if the controller controlling the exchange fails, this not only affects the user but also leads to revenue loss as all metering information for on-going calls will be lost. So, most service providers expect exchange controllers, and not the subscriber interface, to be fault-tolerant.


There are certain applications like aircraft controls and nuclear-plant controls that are critical and failure can be life-threatening. For these systems, fault-tolerance will be implemented based on the criticality of the situation. Let us discuss how FT systems are designed for non-life-threatening applications.
The philosophy of design is very similar for both non-critical and critical systems in handling fault-tolerance. Based on this understanding, we can define FT systems as systems that ensure continued execution of the intended function in case of fault by implementing a combination of hardware and software solutions.
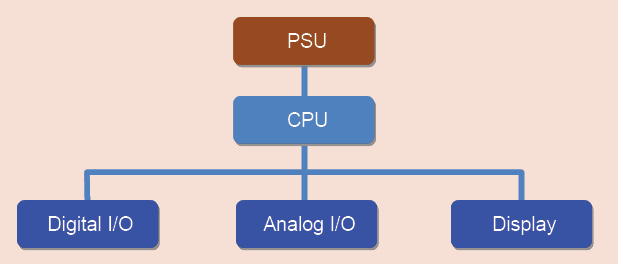
Basics of embedded systems
Fig. 1 shows the block diagram of a conventional embedded system. As you can see, all components/peripherals are tightly-coupled around a CPU into a single entity. This entity can either be a printed circuit board (PCB) or a single chip [also known as system on chip (SoC)]. Typically, FT systems have critical functional components of the system duplicated (in complex and mission-critical applications, there will be multiple units). Most commonly used mechanism is the duplication of the CPU.
Fault-tolerant system architecture characteristics
By definition, an FT system is a system that continues to function the way it is designed even in the event of component failure. The basics are:
1. Any fault that has an impact on human life or revenue is handled by FT systems. However, the level and intensity of fault-tolerance varies with criticality of applications.
For example, in a telephone exchange, when a controller fails and the system is not fault-tolerant, all subscribers connected to the exchange suffer, leading to customer dissatisfaction as well as loss of revenue due to the loss of data. So, most controllers in a telephone exchange are fault-tolerant. Whereas, if a subscriber line or the interface connecting to the exchange fails, only that subscriber is affected.

In applications in nuclear plant systems and avionics, implementation of fault-tolerance is based on the criticality of the function.
2. Fault-tolerance is implemented as a combination of hardware and software in the system.
3. Non-life-threatening FT systems are designed to handle single faults, at any given time. Technically, handling multiple faults is feasible but the cost and complexity of the system is directly proportional to the number of faults concurrently handled. Higher the number of faults handled, more expensive and complex the system will be.
In this article we will discuss FT systems that handle only single faults. However, the philosophy of design for multiple faults is the same as single faults, barring the complexity of the design.
Understanding fault-tolerant architecture
Fault-tolerant architectures are classified into three major categories.
1. Duplication of frequently failing units (typically, power supply units)
2. Duplication of CPUs
3. CON-MON architecture (not a full-fledged FT system)
In all these systems, we need to keep in mind that the solution is a combination of hardware and software. Let us look at each of these in detail.
layer (HAL) between the hardware and OS, so that
porting OS becomes easy
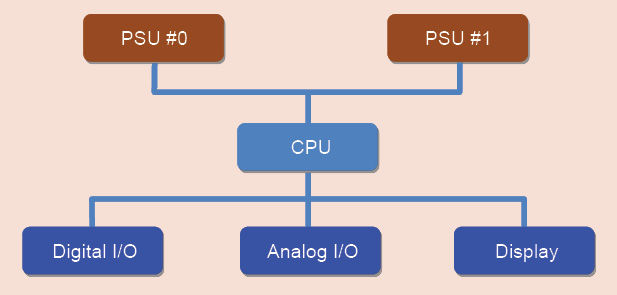
Duplication of power supply units (PSUs). The simplest part of FT architecture is designing a system with duplicated power supplies. This approach works in systems where power densities are high and PSUs fail frequently because of heavy load. This architecture is easy to implement as it does not call for big design changes in the main system. Fig. 2 shows the FT architecture of duplicated PSUs.
In this architecture, when one PSU fails, the other takes over. This means that, despite two PSUs being present, only one will take the full load, stressing the active PSU. This mode is also known as hot-stand-by mode.
So, to improve the architecture, modifications are made so that PSUs share the load equally, and when one of them fails, the other takes 100 per cent of the load. This mode is known as load-sharing mode. Since PSUs in load-sharing mode are loaded only to half their capacities. This approach needs a current-sharing feature in the power supply, which makes the PSU design complex.
But there is no restriction on the number of PSUs that can be added. In telecom applications, some core systems tend to have three PSUs in the current-sharing mode so that PSUs are not loaded more than 60 per cent of their capacities to ensure reliable working.
To implement a duplicated PSU FT system, some system features need to be incorporated, such as:
1. In hot-stand-by mode or current-sharing mode, the main system should be intimated about the failure through hardware signal so that the system raises an alarm and the faulty system can be repaired.
2. When the system runs in hot-stand-by mode, the main system needs to periodically switch the PSU so that both PSUs are tested continuously.
3. In both cases, the system should have the option of PSU hot-plug-in. This ensures smooth running of the main system when a new PSU is introduced.
Duplicated control unit based FT systems. When the system has to be completely fault-tolerant, duplication beyond the PSU is needed as other faults may still cause problems despite having duplicated PSUs in place. In the duplicated controller architecture, CPUs are duplicated so that, if one CPU or associated logic fails, the other CPU takes over. Duplicated CPU based FT systems are based on a combination of hardware and software.
Fig. 6: High-level software architecture for FT systems
The FT mechanism works on two essential features that the processors have—watchdog timer and high-speed serial or parallel link between two CPUs. Fig. 3 shows how duplicated CPU based FT systems are implemented.
When an FT system based on duplicated CPUs is implemented, the following three aspects need to be understood well:
1. Time taken for the good CPU to take over from the faulty one (known as switch-over time)
2. Consistency of system data and user data between the two CPUs (data integrity)
3. Interface to the common control element by the two CPUs (redundant CPU bus interface)
4. Built-in diagnostics to identify and isolate problems in the system periodically (built-in self-test)
As we can see, duplicated CPUs work as a combination of hardware and software elements. Let us see how the system is implemented to help us understand the FT operation well.
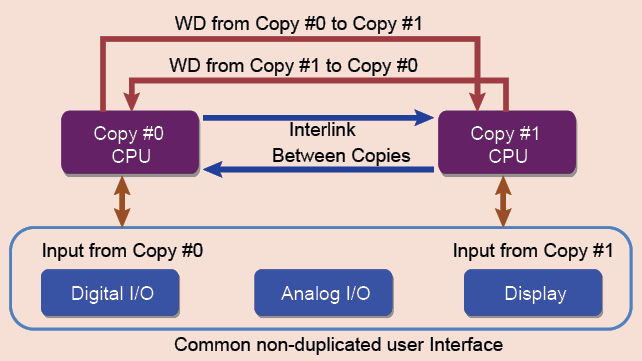
Duplicated CPU based system uses two CPU circuit boards (which are identical) with two types of interconnections between them. Each CPU has a signal called watchdog out (WD OUT) and watchdog in (WD IN), and high-speed interlink in (HS-ILNK-IN) and high-speed interlink out (HS-ILNK-OUT). Since the system has only duplicated controllers, these are connected to common functions that they control (Fig. 3).
These common functions receive control and data from both CPUs. Hence, the common function should have the facility to be controlled by either CPU. Also, if an FT system has to be implemented, it has to be done from the concept phase covering both hardware and software.
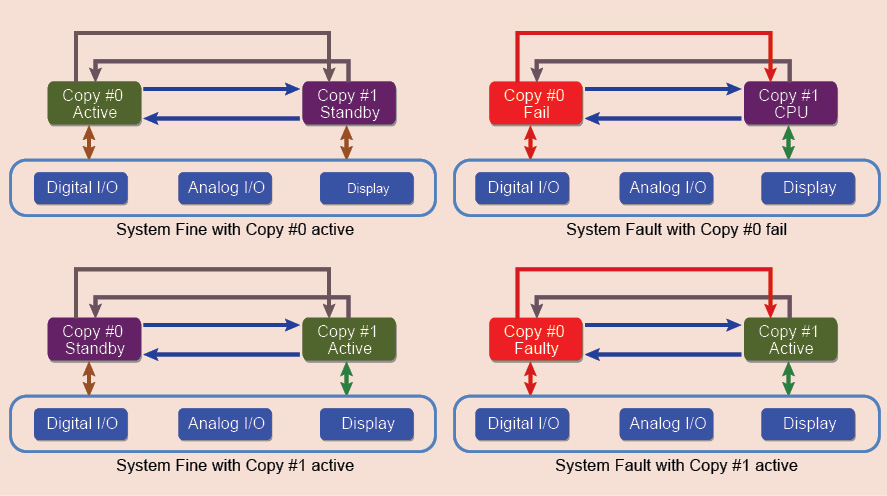
How a duplicated CPU FT system works. When the system starts, both CPUs are good and either of them can control the system. This is implemented by a hardware based dice mechanism, which is similar to a coin-toss function. At the start, the dice circuit will randomly make one CPU active.
Typically, in a duplicated CPU FT system, CPUs are called copy #0 and copy #1. So, at the start itself, one of them is actively controlling the system. Both CPUs will be punching the watchdog, so that no time-out occurs. At the same time, the system software through the high-speed interlinks updates all critical data on a run-time basis, so that both CPUs are in identical states. This mode is called duplex mode.
When the active copy develops a fault (Fig. 4), it fails to punch the watchdog and a time-out occurs. This triggers a signal to the other copy, which straightaway takes control of the system and raises an alarm, indicating that the CPU switch-over has happened. This mode is called simplex mode.
In the meanwhile, the faulty CPU with a watchdog timer restarts and runs self-diagnostics to identify whether the problem is related to hardware or software. If the problem lies with hardware, it displays the fault and calls the attention of the user for a replacement. Meanwhile, the copy that took over the system controls and runs as usual, so that the main functionality of the system does not suffer. Fig. 4 shows the sequence of events.
It is the system software’s responsibility to maintain the log that the faulty unit has been replaced with a good one and the system has returned to duplex mode.
At this stage we need to understand that dual CPU implementation has two variations in their working, based on software implementation.
An FT system is fully-controlled by one CPU and the other CPU takes over when the active one fails. This is known as hot-stand-by architecture. Here, the software is simple and two critical elements need to be handled, namely, the take-over portion of the software and system/user parameters update through the interlink.
The second variation, which is complex in software implementation but more precise, is known as load-sharing architecture. In this architecture, both CPUs execute the system software, while the active one controls the system. The status of the system is almost identical and the CPU load is shared for better functionality. This architecture helps in mission-critical systems for faster take-over and control.
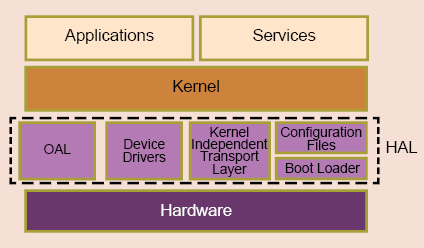
The system software is very critical, despite the choice of architecture. Since most FT systems are real-time systems, these use real-time operating systems (RTOSs) or real-time kernels (RTKs). This complicates the development of FT software. Typically, all RTOSs/RTKs have a hardware-abstraction layer (HAL) (Fig. 5) between the hardware and OS, so that porting OS becomes easy. This software is written specifically for each processor, so that application developers are completely decoupled from the processors used.
When an FT system is being implemented, its performance is dependent on the way FT software is implemented in a classical RTOS/RTK application. Integrating it with HAL will give the fastest performance when handling WD timer run-out. However, updates through interlink need a complete link-handling driver.
Since the interconnect link can be anything including a simple serial port, an Ethernet link or a custom parallel bus, the update section of the software is critical. The challenge is that the software engineer, who is building the FT software, needs to work with the hardware team, as well as understand the system requirement, to implement the interlink update software.
Let us say we are implementing an FT system for a telephone exchange. From the revenue point of view, both duplicated controllers should be consistent for all billing data of on-going calls. With a metering data resolution of one second, and let us say that this controller handles about 500 customers, link speed of 2Mbps to 5Mbps will be good for consistency. The choice of interlink is based on the system’s need and the smallest resolution that the system has to handle. This is a critical aspect that every implementer should be aware of.
Often, the interlink speed and performance requirement is an after-thought, leading to sub-optimal performance of the system. Fig. 6 shows the high-level software architecture for FT systems.
For mission-critical systems, like avionics, railway-signalling controllers, medical devices and nuclear plant systems, a failure may be life-threatening. These systems have multiple CPUs (three or more) and use a complex, majority logic based voting system to implement the FT system.
CON-MON architecture. One of the unique architectures frequently used in avionics and other systems is CON-MON architecture. The name CON-MON stands for control-and-monitor processor architecture. This architecture is not fault-tolerant as the main function of this architecture is to sound an alarm when the main CPU fails. It uses two CPUs—the main CPU, which controls the function of the system, and a small microcontroller, which monitors the main CPU through the WDT run-out.
You may think what the advantage of this architecture is. Let us assume that the small microcontroller is not there. When the main CPU restarts due to a fault, details about the fault, like the time and duration, are lost, and failure is known only when the main CPU stops working. With the CON-MON architecture, the smaller controller will log this data, apart from raising the alarm.
