


 Machine learning is a rapidly growing field which enables computers to learn patterns in the objects surrounding us. It is still a growing field with much more discoveries to be awaited, today machine learning algorithms can be used to teach computers to perform wide varieties of tasks. This includes task like detection of objects in an image, speech recognition, autonomous driving etc. This tutorial will provide a high-level introduction to the field of machine learning. To get a sense of how machine learning work, we begin our tutorial with a simple example of how a computer can recognize cats from other animals. Along with this, we provide a python code from implementing the same.
Machine learning is a rapidly growing field which enables computers to learn patterns in the objects surrounding us. It is still a growing field with much more discoveries to be awaited, today machine learning algorithms can be used to teach computers to perform wide varieties of tasks. This includes task like detection of objects in an image, speech recognition, autonomous driving etc. This tutorial will provide a high-level introduction to the field of machine learning. To get a sense of how machine learning work, we begin our tutorial with a simple example of how a computer can recognize cats from other animals. Along with this, we provide a python code from implementing the same.
To teach a growing child about the difference between cats and dogs, we never provide any scientific description of these animals from Wikipedia. Instead of it, a child is naturally presented with images of a wide variety of animals and what is told to them is that the animal is either cat or dog until they are fully grasped with this concept. How do we know when a child has learned to correctly distinguish between cats and dogs? It is when they encounter the new set of images of cats and dogs which they have never seen before and they successfully classify them as cats and dog’s image. Likewise, computers can be made to learn in the same fashion and this is referred to as classification problem in the area of machine learning. A typical machine learning follows the following pipeline
Data Collection:
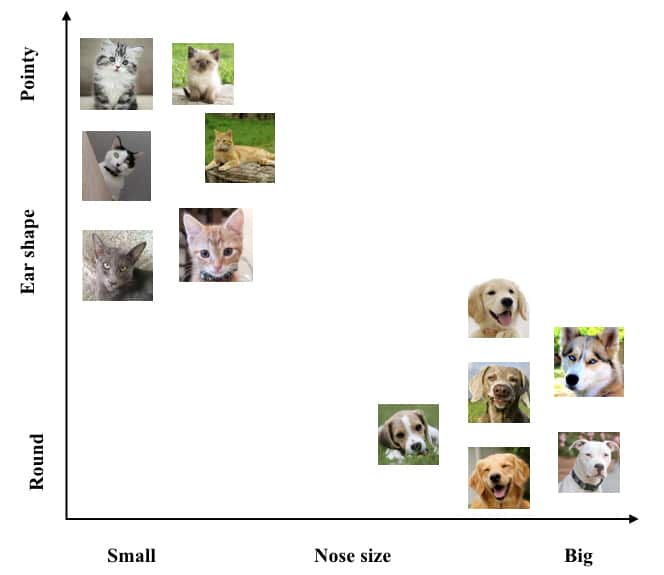
Like human beings, computers must be trained to distinguish between the two types of animals namely, dogs and cats by presenting them with the series of images. This is referred to as training set of data. Fig. 1 shows one such example of training set consisting of few images of cats and dogs. The larger and more diverse the training set the better a computer can perform a learning task.



Features designing:
Think for a second about how you yourself tell the difference between the images of cats and dogs. What do you think you look for in the pictures to tell the difference? You will definitely use color, size, shape of the ears or nose, and the combination of these features to distinguish between the two animals. In other words, you just do not look at the image as simply a collection of pixels instead you pick out features from the image in order to identify between cats and dogs. This is true for computers as well. In order to successfully train a computer to perform the task of classification, we need to provide it with properly designed features or we have to find such features itself.
This is not an easy task as it seems because designing good quality features is very application dependent. For example, a feature like “number of legs” would come to be totally unhelpful in discriminating between cats and dogs as both of them have four legs! but quite helpful in discriminating between cats and snakes. Further, extracting features from an image can be sometimes challenging. For instance, if images are blurry, the features will not be properly extracted. For our example, we can easily extract two features from each image of the training set:

(a) size of the nose, relative to the size of the head (from small to big)
(b) shape of the ears (from round to pointy)
Examining the images in the training set (Fig. 1), we can observe that all the cats have a small nose and pointy ears while dogs have a long nose and round ears. With the current choice of features, each image can be represented using two numbers: a number expressing relative nose size and another number capturing pointiness or round ears. Hence, we can now represent our training set in a two-dimensional feature space where the feature nose size and ears shape is on horizontal and vertical axes as shown in Fig 2.
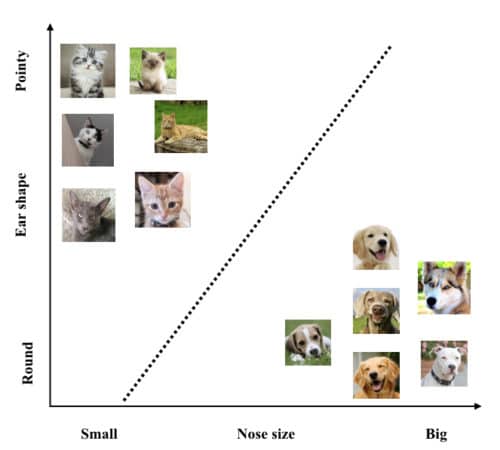
Training Phase:
Now we have good feature representation of our images in the training set, the final task is now teaching a computer to distinguish between cats and dogs. It is a simple geometric problem where the computer has to find a line that separates the two images in our designed feature space. Since the line is parameterized by a slop and intercept, this means finding the right values for the both. Fig. 3 shows the trained line which divides the feature space into cats and dogs respectively. Once the line is obtained, any future image whose features lie above the line will be considered a cat by the computer, and likewise, any feature representation that falls below the line will be considered a dog.
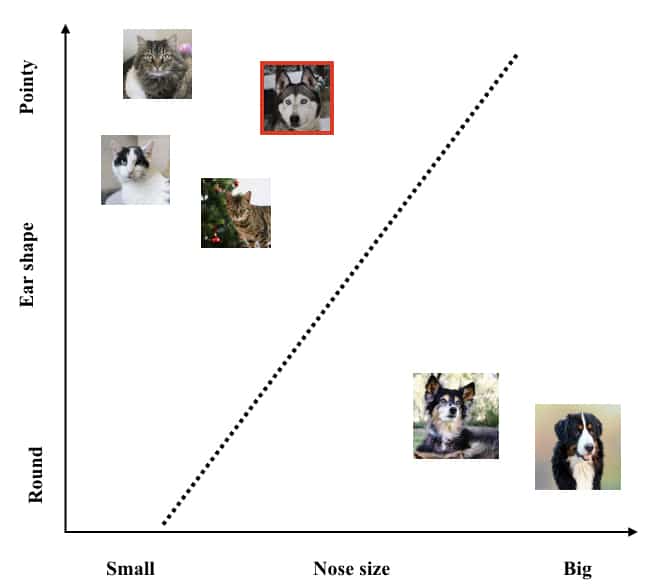
Model testing:
In order to test the computer on how well it has learned to distinguish between cats and dogs, we provide it with the series of images not seen earlier and see how well it can identify the animal in each image. In Fig. 4 we show the sample of testing images consisting of three new cat and dogs not seen by the computer during the training phase. So, what computer does is it will take the features into account and check on which side of the line these images will fall. For instance, it can be observed in Fig. 5 all the new cats and all but one dog from the testing set have been identified properly. The misidentification of one of the dogs (shown in the red box) is completely due to our choice of features which we designed using training set as shown in Fig 1.
This dog is misunderstood as cat simply because its feature i.e. sizes of the nose and shape of the ears match with that of cats in the training set. To reduce this problem, we should train our computer with more training data and use more discriminating features that will help to distinguish cats from dogs.


To supplement this article, we are providing python script for recognizing cats from other animals. It has a database which consists of all kinds of animals and our algorithm will predict whether the image you uploaded to the software is a cat or not.
