




Researchers from Stanford have developed a new tool that enables the students to break down a video and transcript for improved note-taking and comprehension.
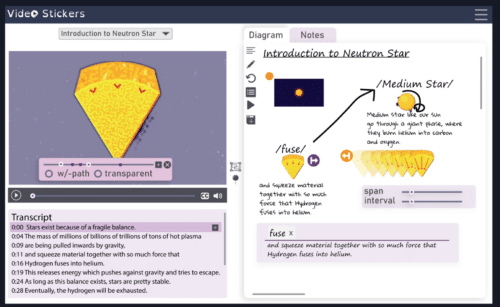
With the growth of technology, video has become a predominant mode of learning. Video functions as a powerful medium for educating students when compared to the text or lecture-based instructions. However, it can be difficult to find the content that has been viewed already, complicating the process of note-taking.

A team of researchers headed by Hari Subramonyam from the University of California have harnessed computer vision and natural language processing tools, developing VideoSticker. VideoSticker combines video, audio, transcripts, visual and textual note-taking applications. Using AI, it can identify and trim objects and place them into the respective note taking area automatically. It bounces back and forth of the video for accuracy in note-taking.
VideoSticker combines transcription tools that are also used for voice recognition and chatbots to pull key text, in accordance with the imagery. These functions and tools allow students to focus on the important content and to improve comprehension.
Research shows that the students learn the best through models of concepts. These models can be of any form – maps, diagrams, timeline, visualization and notes.
VideoSticker turns the passive experience of simply watching video into an active one where the students can learn easily. It manipulates the images and texts by combining their own explanations and comments for better comprehension and recall.

“Video is most often associated with entertainment, and that’s a very different experience from an educational context for knowledge gathering,” Subramonyam says. “More and more, we’re asking students in the TikTok era to consume hour-long videos and learn key concepts. Right now, they just don’t have the adequate software tools for that. VideoSticker fills that void.”
