




Researchers have demonstrated a low-power, wearable interface that requires just a few minutes of user training data to recognize silent speech.
Individuals unable to produce vocal sounds find it challenging to express themselves. A technology that can restore their speaking ability can benefit them in numerous ways.

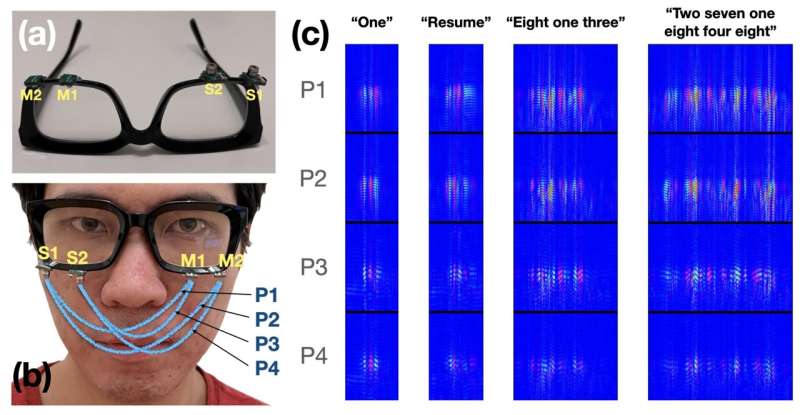
The researchers at Cornell University have developed an unspoken word recognition interface using AI and acoustic-sensing, recognizing up to 31 unvocalized commands from lip and mouth movements. EchoSpeech is a wearable, low-power interface that needs minimal user training data, runs on a smartphone, and can recognize commands.
EchoSpeech enables communication via smartphone in noisy or quiet places and can be paired with a stylus for design software like CAD, reducing the need for a keyboard and mouse.

EchoSpeech glasses use microphones and speakers smaller than pencil erasers to send and receive sound waves across the face and detect mouth movements. A deep learning algorithm then analyzes these echoes in real-time with 95% accuracy. It advances performance and privacy in wearable tech with small size, low power, and privacy sensitivity, which is critical for real-world deployment.
Most silent-speech recognition technology is usually limited to preset commands and needs camera facing or wearing, which is impractical and infeasible. Privacy concerns arise with wearable cameras for the user and those around them. EchoSpeech’s acoustic-sensing tech eliminates the need for wearable video cameras and requires less bandwidth to process than image or video data. Hence it can be relayed to a smartphone via Bluetooth in real-time.
Researchers believe that privacy-sensitive information always remains in control since the data is processed locally on your smartphone instead of being uploaded to the cloud.
Reference : Conference: chi2023.acm.org/ Research: ruidongzhang.com/files/papers/ … _authors_version.pdf
