



Researchers have developed a new text-to-speech system that can create high-quality audio with unique text samples in seconds with very little computing power.
Researchers at University of Surrey are inviting the public to test out their new text-to-audio model as they believe generative artificial intelligence (AI) systems will inspire an explosion of creativity in the music industry and beyond.

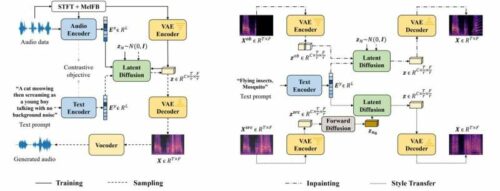
Their new AI-based system, AudioLDM, allows users to submit a text prompt, which is then used to generate a corresponding audio clip. The system can process prompts and deliver clips using less computational power than current AI systems without compromising sound quality or the users’ ability to manipulate clips.
Surrey’s open-sourced model is built in a semi-supervised way with a method called Contrastive Language-Audio Pretraining (CLAP). Using the CLAP method, AudioLDM can be trained on massive amounts of diverse audio data without text labeling, significantly improving model capacity.
Haohe Liu, project lead from the University of Surrey, said, “Generative AI has the potential to transform every sector, including music and sound creation. With AudioLDM, we show that anyone can create high-quality and unique samples in seconds with very little computing power. While there are some legitimate concerns about the technology, there is no doubt that AI will open doors for many within these creative industries and inspire an explosion of new ideas.”

Wenwu Wang, professor in signal processing and machine learning at the University of Surrey, said, “What makes AudioLDM special is not just that it can create sound clips from text prompts, but that it can create new sounds based on the same text without requiring retraining.”
“This saves time and resources since it doesn’t require additional training. As generative AI becomes part and parcel of our daily lives, it’s important that we start thinking about the energy required to power up the computers that run these technologies. AudioLDM is a step in the right direction.”
Reference : Haohe Liu et al, AudioLDM: Text-to-Audio Generation with Latent Diffusion Models, arXiv (2023). DOI: 10.48550/arxiv.2301.12503
