



Artificial intelligence (AI) and machine learning (ML) are now considered a must to enhance solutions in every market segment with their ability to continuously learn and improve the experience and the output. As these solutions become popular, there is an increasing need for secure learning and customisation. However, the cost of training the AI for application-specific tasks is the primary challenge across the market
The challenge in the market for AI to get more scaled is just the cost of doing AI. If you look at GPT-3, a single training session costs weeks and $6 million! Therefore, every time a new model or a change is presented, again the count starts from zero and the current model needs to be retrained, which is quite expensive. Variety of things affect the training of these models, such as drift, but the need to retrain for customisation would certainly help in managing retraining cost.
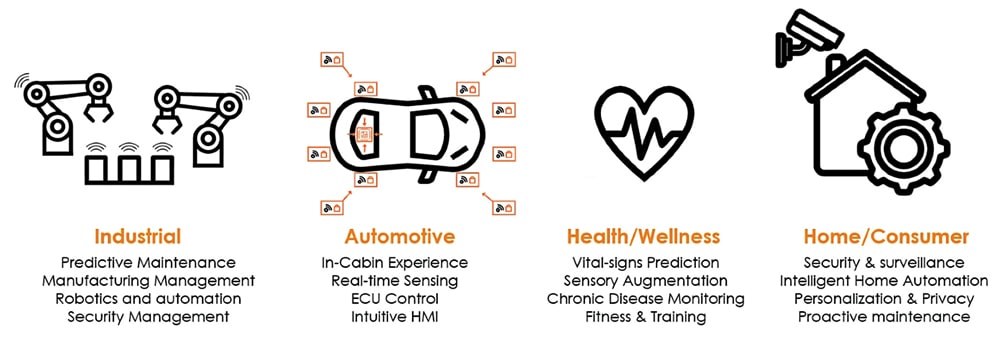
Consider the manufacturing industry, which is projecting losses of about $50 billion per year because of preventable maintenance issues. There is downtime cost because the maintenance wasn’t done in time. Another staggering statistic shows the loss of productivity in the US due to people not coming to work because the cost of preventable chronic diseases is $1.1 trillion. That is just the productivity loss, not the cost of healthcare.

This could have been substantially reduced by more capable and cost-effective monitoring through digital health. Therefore, a need of real-time AI close to the device to help learn, predict, and correct issues and proactively schedule maintenance is duly necessary.
AI is fueled by data, so one needs to consider the amount of data that is being generated by all the devices. Let us consider just one car. A single car generates data that ranges over a terabyte per day. Imagine the cost of actually learning from it. Imagine how many cars are there generating that kind of data? What does it do to the network? While not all of that data is going to the cloud, a lot of that data is being stored somewhere.
These are a few of both the opportunities or problems that AI can solve, but also the challenges that are preventing AI from scaling to deliver those solutions. The real questions can be framed as follows:
• How do we reduce the latency and therefore improve the responsiveness of the system?
• How do we actually make these devices scale? How can we make them cost effective?
• How do you ensure privacy and security?
• How to tackle network congestion due to the large amount of data generated?
The solution
A variety of factors affect the latency of a system. For example, the hardware capacity, network latency, and the use of large amounts of data is also a problem. These devices embed AI, they also have the self-learning abilities based on the innovative time series data handling for predictive analysis. Predictive maintenance is an important factor in any manufacturing industry as most of the industries are now turning to robotic assembly lines. In-cabin experience, for example, utilises a similar AI enabled environment, even for automated operation of autonomous vehicles (AVs). Sensing the vital signs prediction and analysis of the medical data is an important health and wellness application example. Security and surveillance as well are now turning towards AI enabled security cams for continuous surveillance.
“The more intelligent devices you make, the greater the growth of the overall intelligence.”
The solution to latency lies in a distributed AI computing model, which is a strong component with the ability to embed edge AI devices, to have the performance to run necessary AI processing. More importantly, we need the ability to learn on the device to allow for secure customisation, which can be achieved by making these systems event based.
This will reduce the amount of data and eliminate sensitive data being sent to the cloud, thereby reducing network congestion, cloud computation, and improve security. It also provides real-time responses, which makes timely actions possible. Such devices become compelling enough for people to buy as it’s not only about the performance but how you make it cost-effective as well.
Neural devices are trained generally in two ways, either using the machine fed data or using spikes that mimic the functionality of spiking neural networks. This makes the system loaded.
A neural system, on the other hand, requires an architecture that can accelerate all types of neural networks, may it be convolution neural network (CNN), deep neural network (DNN), spiking neural network (SNN), or even vision transformers or sequence prediction.
Therefore, using a stateless architecture in distributed systems can help reduce the load on servers and the time it takes for the system to store and retrieve data. Stateless architecture enables applications to remain responsive and scalable with a minimal number of servers, as it does not require applications to keep record of the sessions.
Using direct media access (DMA) controllers can boost responsiveness as well. This hardware device allows input-output devices to directly access the memory with less participation of the processor. It’s like dividing the work among people to boost the overall speed, and that is exactly what happens here.
Intel Movidius Myriad X, for example, is specifically a vision processing unit that has a dedicated neural compute engine that directly interfaces with a high-throughput intelligent memory fabric to avoid any memory bottleneck when transferring data. The Akida IP Platform by BraiChip also utilises DMA in a similar manner. It also has a runtime manager that manages all operations of the neural processor with complete transparency and can also be accessed through a simple API.
Other features of these platforms include the multi-pass processing, which is processing multiple layers at a time, making the processing very efficient. One ability of the device is the smaller footprint integration to make fewer nodes in a configuration and go from a parallel type execution to a sequential type execution. This means latency.
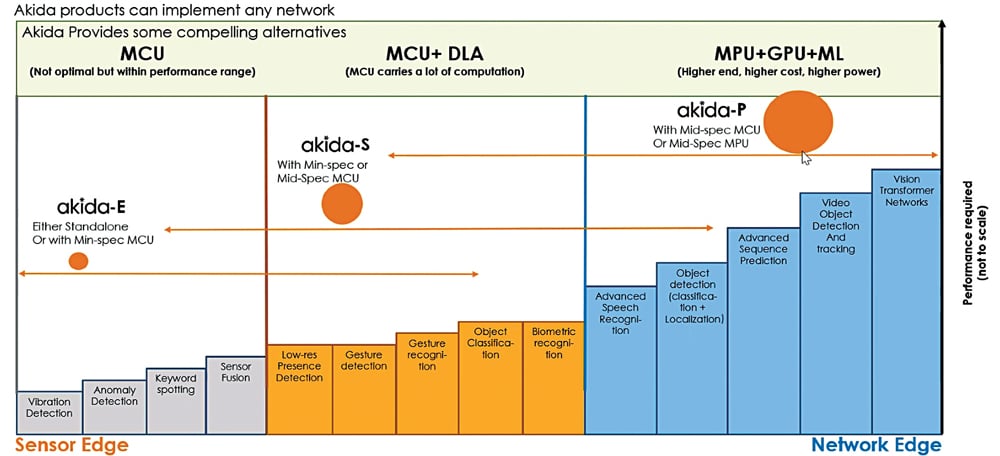
But a huge amount of that latency comes from the fact that the CPU gets involved every time a layer comes in. As the device processes multiple layers at a time, and the DMA manages all activity itself, latencies are significantly reduced.
Consider an AV, which requires the data to be processed from various sensors at a time. The TDA4VM from Texas Instruments Inc. comes with a dedicated deep-learning accelerator on-chip that allows the vehicle to perceive its environment by collecting data from around four to six cameras, a radar, lidar, and even from an ultrasonic sensor. Similarly, the Akida IP Platform can do larger networks on a smaller configuration simultaneously.
Glimpse into the market
These devices have a huge variety of scope in the market. As these are referred to as event based devices, they have an application sector. For example, Google’s Tensor processing units (TPUs), which are application-specific integrated circuits (ASICs), are designed to accelerate deep learning workloads in their cloud platform. TPUs deliver up to 180 teraflops of performance, and have been used to train large-scale machine learning models like Google’s AlphaGo AI.
Similarly, Intel’s Nervana neural network processor is an AI accelerator designed to deliver high performance for deep learning workloads. The processor features a custom ASIC architecture optimised for neural networks, and has been adopted by companies like Facebook, Alibaba, and Tencent.
Qualcomm’s Snapdragon neural processing engine AI accelerator is designed for use in mobile devices and other edge computing applications. It features a custom hardware design optimised for machine learning workloads, and can deliver up to 3-terflop performance, making it suitable for on-device AI inference tasks.
Several other companies have already invested heavily in designing and producing neural processors that are being adapted into the market as well, and that too in a wide range of industries. As AI, neural networks, and machine learning are becoming more mainstream, it is expected that the market for neural processors will continue to grow.
In conclusion, the future of neural processors in the market is promising, although many factors may affect their growth and evolution, including new technological developments, government regulations, and even customer preferences.
This article, based on an interview with Nandan Nayampally, Chief Marketing Officer, BrainChip, has been transcribed and curated by Jay Soni, an electronics enthusiast at EFY
Nandan Nayampally is Chief Marketing Officer at BrainChip
