



We are witnessing the AI revolution. In order to make smart decisions, the devices equipped with AI need lots and lots of data. And making sense of that data needs power and speed. This is where AI accelerators come into the picture.
As IoT systems are getting more and more efficient, data acquisition is getting easier. This has increased the demand for AI and ML applications in all smart systems. AI based tasks are data-intensive, power-hungry, and call for higher speeds. Therefore, dedicated hardware systems called AI accelerators are used to process AI workloads in a faster and more efficient manner.
Co-processors like graphics processing units (GPUs) and digital signal processors (DSPs) are common in computing systems. Even Intel’s 8086 microprocessor can be interfaced with a math co-processor, 8087. These are task-driven additions that were introduced because CPUs alone cannot perform their functions. Similarly, CPUs alone cannot efficiently take care of deep learning and artificial intelligence workloads. Hence, AI accelerators are adopted in such applications. Their designs revolve around multi-core processing, enabling parallel processing that is much faster than the traditional computing systems.


At the heart of ML is the multiply-accumulate (MAC) operation. Deep learning is primarily composed of a large number of such operations. And these need to happen parallelly. AI accelerators have the capacity to significantly reduce the time it takes to perform these MAC operations as well as to train and execute AI models. In fact, Intel’s head of architecture, Raja Koduri, noted that one day every chip will be a neural net processor. This year, Intel plans to release its Ponte Vecchio HPC graphics card (accelerator), which, Intel claims, is going to be a game-changer in this arena.

User-to-hardware expressiveness
‘User-to-hardware expressiveness’ is a term coined by Adi Fuchs, an AI acceleration architect in a world-leading AI platforms startup. Previously, he has worked at Apple, Mellanox (now NVIDIA), and Philips. According to Fuchs, we are still unable to automatically get the best out of our hardware for a brand new AI model without any manual tweaking of the compiler or software stack. This means we have not yet effectively reached a reasonable user-to-hardware expressiveness.

It is surprising how even slight familiarity with processor architecture and the hardware counterpart of AI can help in improving the performance of our training models. It can help us understand the various bottlenecks that can cause the performance of our models to decrease. By understanding processors, and AI accelerators in particular, we can bridge the gap between writing code and having it implemented on the hardware.

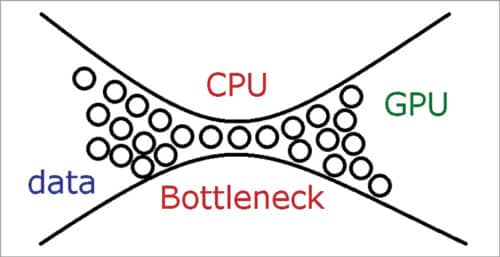
Bottleneck in AI processing
As we add multiple cores and accelerators to our computing engines to boost performance, we must keep in mind that each of them has a different speed. When all these processors work together, the slowest one creates a bottleneck. If you use your PC for gaming, you would probably have experienced this problem. It does not matter how fast your GPU is if your CPU is slow.
Similarly, it would not matter how fast hardware accelerators are if the read/write data transfer is slow between RAM storage and the processor. Hence, it is crucial for designers to select the right hardware for all components to be in sync.
 Popular AI accelerator architectures
Popular AI accelerator architectures
Here are some popular AI architectures:
Graphics processing unit (GPU)
Well, GPUs were not originally designed for ML and AI. When AI and deep learning were gaining popularity, GPUs were already in the market and were used as specialised processors for computer graphics. Now we have programmable ones too, called general-purpose GPU (GPGPU). Their ability to handle computer graphics and image processing makes them a good choice for usage as an AI accelerator. In fact, GPU manufacturers are now modifying their architectures for use in AI or ML.

In 2012, Alex Krizhevsky, Ilya Sutskever, and Geoffrey Hinton from the University of Toronto presented a paper on AlexNet, a deep neural network. It was trained on readily available, programmable consumer GPUs by NVIDIA (NVIDIA GTX 580 3GB GPU). It is basically a GPU implementation of a CNN (convolutional neural network). AlexNet won the 2012 ImageNet Large Scale Visual Recognition Challenge (ILSVRC).
FPGAs and ASICs. FPGAs are semiconductor devices that, as the name suggests, are field programmable. Their internal circuitry is not mapped when you buy them; you have to program them right on the field using hardware description languages (HDLs) like VHDL and Verilog. This means that your code is converted into a circuit that is specific to your application. The fact that they can be customised gives them a natural advantage over GPUs.
Xilinx and an AI startup called Mipsology are working together to enable FPGAs to replace GPUs in AI accelerator applications, just using a single command. Mipsology’s software Zebra converts GPU code to run on Mipsology’s AI compute engine on an FPGA, without any code changes.

FPGAs are cheaper, reprogrammable, and use less power to accomplish the same work. However, this comes at the cost of speed. ASICs, on the other hand, can achieve higher speeds and consume low power. Moreover, if ASICs are to be manufactured in bulk, the costs are not that high. But they cannot be reprogrammed on the field.
Tensor processing unit (TPU). Tensor processing unit is an AI accelerator built by Google specifically for neural network machine learning. Initially, it was used by Google only, but since 2018, Google has made it available for third-party use. It supports TensorFlow code and allows you to run your own programs on the TPU on Google Cloud. The documentation provided by Google is comprehensive and includes several user guides. The TPU is specifically designed for vector-by-matrix multiplication, an operation that happens multiple times in any ML application.
 On-edge computing and AI
On-edge computing and AI
On-edge computing gives an engine the power to compute or process locally with low latency. This leads to faster decision-making due to faster response time. However, the biggest advantage would be the ability to send just the processed data to the cloud. Hence, with edge computing, we will no longer be as dependent on the cloud as we are today. This means that lesser cloud storage space is required, and hence lower energy usage and lower costs.

The power consumed by AI and ML applications is no joke. So, deploying AI or machine learning on edge has disadvantages in terms of performance and energy that may outweigh the benefits. With the help of on-edge AI accelerators, developers can leverage the flexibility of edge computing, mitigate privacy concerns, and deploy their AI applications on edge.
Boards that use AI accelerator
As more and more companies make a mark in the field of AI accelerators, we will slowly witness a seamless integration of AI into IoT on edge. Companies like NVIDIA are, in fact, known for their GPU accelerators. Given below are a few examples of boards that feature AI accelerators or were created specifically for AI applications.
Google’s Coral Dev Board. Google’s Coral Dev Board is a single-board computer (SBC) featuring an edge TPU. As mentioned before, TPUs are a type of AI accelerator developed by Google. The edge TPU in the Coral Dev Board is responsible for providing high-performance ML inferencing with a low power cost.
The Coral Dev Board supports TensorFlow Lite and AutoML Vision Edge. It is suitable for prototyping IoT applications that require ML on edge. After successful prototype development, you can even scale it to production level using the onboard Coral system-on-module (SoM) combined with your custom PCB. Coral Dev Board Mini is Coral Dev Board’s successor with a smaller form factor and lower price.
BG24/MG24 SoCs from Silicon Labs. In January 2022, Silicon Labs announced the BG24 and MG24 families of 2.4GHz wireless SoCs with built-in AI accelerators and a new software toolkit. This new co-optimised hardware and software platform will help bring AI/ML applications and wireless high performance to battery-powered edge devices. These devices have a dedicated security core called Secure Vault, which makes them suitable for data-sensitive IoT applications.

The accelerator is designed to handle complex calculations quickly and efficiently. And because the ML calculations are happening on the local device rather than in the cloud, network latency is eliminated. This also means that the CPU need not do that kind of processing, which, in turn, saves power. Its software toolkit supports some of the most popular tool suites like TensorFlow.
“The BG24 and MG24 wireless SoCs represent an awesome combination of industry capabilities, including broad wireless multiprotocol support, battery life, machine learning, and security for IoT edge applications,” says Matt Johnson, CEO of Silicon Labs. These SoCs will be available for purchase in the second half of 2022.
MAX78000 Development Board by Maxim Integrated. The MAX78000 is an AI microcontroller built to enable neural networks to execute at ultra-low power. It has a hardware based convolutional neural network (CNN) accelerator, which enables battery-powered applications to execute AI inferences.
Its CNN engine has a weight storage memory of 442kB and can support 1-, 2-, 4-, and 8-bit weights. Being SRAM based, the CNN memory enables AI network updates to happen on the fly. The CNN architecture is very flexible, allowing networks to be trained in conventional toolsets like PyTorch and TensorFlow.
Kria KV260 Vision AI Starter Kit by Xilinx. This is a development platform for Xilinx’s K26 system on module (SOM), which specifically targets vision AI applications in smart cities and smart factories. These SOMs are tailored to enable rapid deployment in edge based applications.
Because it is based on an FPGA, the programmable logic allows users to implement custom accelerators for vision and ML functions. “With Kria, our initial focus was Vision AI in smart cities and, to some extent, in medical applications. One of the things that we are focused on now and moving forward is expanding into robotics and other factory applications,” says Chetan Khona, Director of Industrial, Vision, Healthcare & Sciences markets at Xilinx.
Gluon AI co-processor by AlphaICs. The Gluon AI accelerator is optimised for vision applications and provides maximum throughput with minimum latency and low power. It comes with an SDK that ensures easy deployment of neural networks.
AlphaICs is currently sampling this accelerator for early customers. It is engineered for OEMs and solution providers targeting vision market segments, such as surveillance, industrial, retail, industrial IoT, and edge gateway manufacturers. The company also offers an evaluation board that can be used to prototype and develop AI hardware.

Intel’s Neural Compute Stick 2 (Intel NCS2). Intel’s NCS2 looks like a USB pen drive but actually brings AI and computer vision to edge devices in a very easy manner. It contains a dedicated hardware accelerator for deep neural network interfaces and is built on the Movidius Myriad X Vision processing unit (VPU).
Apart from using the NCS2 for their PC applications, designers can even use it with edge devices like Raspberry Pi 3. This will make prototyping very easy and will enhance applications like drones, smart cameras, and robots. Setting up and configuring its software environment is not complex, and detailed tutorials and instructions on various projects are provided by Intel.
A long way to go
The field of AI accelerators is still niche, and there is still a lot of room for innovation. “Many great ideas were implemented in the past five years, but even those are a fraction of the staggering number of AI accelerator designs and ideas in academic papers. There are still many ideas that can trickle-down from the academic world to industry practitioners,” says Fuchs.
The author, Aaryaa Padhyegurjar, is an Industry 4.0 enthusiast with a keen interest in innovation and research







Crazy i know about Neural Networks But Don’t Know About Intel’s Neural Compute Stick kind of thing. So Unique And Deep AI News Thank You
You are most welcome.