


In August 2013, computer scientists from Japan and Germany managed to simulate one per cent of human brain activity for a single second. To achieve this apparently simple task, they had to deploy as many as 82,000 processors. These processors were part of Japan’s K computer, the fourth most powerful supercomputer on Earth. The computer scientists simulated 1.73 billion virtual nerve cells and 10.4 trillion synapses, each of which contained 24 bytes of memory. The entire simulation consumed 40 minutes of real, biological time to produce one virtual second.
This shows the complexity and prowess of the human brain. It is extremely difficult to recreate human brain performance using computers, since the brain consists of a mindboggling 200 billion neurons that are interlinked by trillions of connections called synapses. As the tiny electrical impulses shoot across each neuron, these have to travel through these synapses, each of which contains approximately a thousand different switches that direct an electrical impulse.


Human beings have managed to automate increasingly complex tasks. However, perhaps, we have only seen the tip of the iceberg. While a large number of enterprises use information technology (IT) by way of thousands of diverse gadgets and devices, in majority of cases, it is human beings who operate these devices, such as smartphones, laptops and scanners. The intricacy of these systems and the way these link and operate together is leading to the scarcity of skilled IT manpower to manage all systems.
The smartphone has become an integral part of our life today as it often remains connected with our desktop, laptop and tablet. This concurrent burst of data and information and, further, its integration into everyday life is leading to new requirements in terms of how employees manage and maintain IT systems.
As we know, demand is currently exceeding supply of expertise capable of managing multi-faceted and sophisticated computer systems. Moreover, this issue is only growing with the passage of time and our increasing reliance on IT.

The answer to this problem is autonomic computing, that is, computing operations that can run without the need for human intervention.
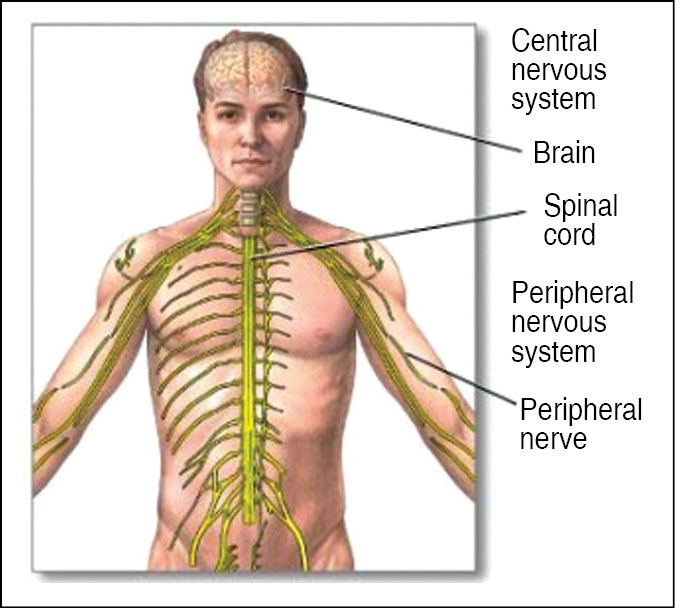
The concept of autonomic computing is quite similar to the way the autonomic nervous system (ANS) (Fig. 1) regulates and protects the human body. The ANS in our body is part of a control system that manages our internal organs and their functions such as heart rate, digestion, respiratory rate and pupillary dilation, among others, mostly below the level of our consciousness. The autonomy controls and sends indirect messages to organs at a sub-conscious level via motor neurons.
In a similar manner, autonomous IT systems are based on intelligent components and objects that can self-govern in rapidly varying and diverse environments. Autonomous computing is the study of theory and infrastructures that can be used to build autonomous systems.
In order to develop autonomous systems, we need to conduct interdisciplinary research across subjects such as artificial intelligence (AI), distributed systems, parallel processing, software engineering and user interface (UI).
Even though AI is a very important aspect for autonomic computing to work, we do not really need to simulate conscious human thoughts as such. The whole emphasis, today, is on developing computers that can be operated intuitively with minimum human involvement. This demands a system that can crunch data in a platform-agnostic manner. And much like the human body, this system is expected to carry out its functions and adapt to its user’s requirements without the need of the user to go into minute details of its functioning.
Self-management in autonomic computing
The very core of autonomic computing systems is self-management, which aims to provide freedom from tasks of system operation and maintenance, and to make available a device that works at peak performance 24 hours a day. The day-to-day working is maintained in a dynamic environment of rapidly and constantly-changing workloads, user requirements and virus attacks, and so on.
The system can also repeatedly keep an eye on its own functioning, for example, let us say, a particular component needs to be checked for upgradation. If an error is detected, the system automatically goes back to the last error-free version, while its problem-determination algorithms work towards identifying and removing the source of the error.



The IBM autonomic computing team has broken the self-management aspect further into four dimensions, namely, self healing, self optimising, self protecting and self controlling.
Self controlling. An autonomic computing system should be able to configure and reconfigure itself under diverse and volatile conditions. The system configuration, or set-up, and the dynamic adjustments to the configuration, in order to manage dynamic environments, must occur automatically.
Self optimising. Interestingly, an autonomic computing system is never satisfied with the status quo and is forever looking for ways to optimise its working. It monitors its constituent elements and makes adjustments to the workflow to achieve predetermined system goals.
Self healing. An autonomic computing system must act like the human body in terms of healing itself. It should be able to bounce back from everyday, as well as unforeseen, problems that might cause some of its parts to fail.
It should be able to find out existing or potential problems and then seek out an alternative way of using resources or reconfiguring the system to keep functioning efficiently.
Self protecting. The virtual world faces as many threats as those faced by a physical world. Hence, an autonomic computing system should be very well-versed in the art of self protection. It should be capable of detecting, identifying and guarding itself against different types of attacks to preserve the overall system security and integrity.
The self-learning aspect
Like human beings, computers are slowly evolving into devices that learn from their own mistakes. The concept is based on the human nervous system, particularly the way our neurons act in response to stimuli and link up with other neurons to construe information. This phenomenon enables computers to digest new information while executing a job and then make changes based on varying inputs.
In the near future, a new generation of AI systems is expected to perform tasks such as speaking and listening, among others, which humans can easily do.
There is a gradual shift from engineering computing systems to one that has several characteristics of biological computing systems since the engineering type is restricted to doing only what these have been programmed for. Biological computing style could be made possible in a few years, such as robots that easily drive and walk in the real world. However, a computer that is capable of thinking may probably take a few decades.

Some application areas
Autonomic computing is expected to simplify the management of computing systems and open doors to applications such as seamless e-sourcing, grid computing and dynamic e-business.
E-sourcing is the ability to bring in IT as a utility, at the time it is required and in the needed quantity to complete the work.
Some other autonomic computing applications areas are memory error correction, server-load balancing, process allocation, monitoring power supply, automatic updating of software and drivers, automated system backup and recovery, and prefailure warning.
Autonomic cloud computing is related to empowering cloud infrastructures and platforms so that these can take their own decisions to incessantly achieve their assigned jobs. Cloud systems are required to consistently deliver their functionalities and facilities to users without any form of human intervention, interpretation and instruction.
Grid computing is one area where autonomic computing equipped with self-managing capabilities can add a lot of value, and there are many related projects in process.
University of Pennsylvania, the USA, is making a potent grid that targets to bring advanced methods of breast cancer diagnosis and screening to patients at a low cost. The grid is a utility-like service delivered over the Internet, enabling hundreds of hospitals to store mammograms in digital form. Analytical tools that aid doctors to diagnose individual cases and discover cancer clusters in the population are also available.
Then, there is North Carolina Biometrics Grid, which is available to thousands of researchers and educators to facilitate boosting the speed of genomic research that is likely to result in new medicines to fight diseases and grow more nutritious foods to satisfy global hunger.
Better access to higher computing power via grid computing integrated with the implementation of open standards will allow researchers to work together more easily on complex issues, which should benefit all mankind.
Weather forecasting and protein folding, where intricate medical calculations are needed, are application areas that need computers to work 24/7, continuously for a couple of years.
Progressively autonomic computers will provide tools to analyse these complex problems. Systems with mobile architecture, such as Blue Gene (Fig. 6), will allow the study of phenomena happening in split seconds at an atomic scale.
Autonomic computing will be able to better harness existing processing power to run complex mathematics for functions such as weather simulations and other scenarios that require public systems and infrastructure.
Human intervention will keep reducing in most tasks linked with systems management in the years to come. In fact, it will seem as pointless as asking a telephone operator for facilitating an STD call looks today.
Autonomic computing will make computers that serve you in some way, just like your airline, telecom operator, bank, and hotel, a reality. We are unlikely to hear responses such as “please try again later as our systems are slow or down.”
At the same time, autonomic features will begin to make way into client-level devices. This will allow the personal computer to finish several jobs, which till now required some level of human intervention, on its own.
Future scope
Perhaps, we have only discovered the tip of the autonomic computing iceberg and are oblivious of the many technical roadblocks that will come in the way. Autonomic computing is at an embryonic stage and there are several critical challenges to be overcome.
Some questions that need to be answered are:
How will we design our systems to define and redefine themselves in dynamic environments? (A system should know its periphery limits before it transacts with other systems.)
How will we build reliable interfaces and points-of-control while permitting a heterogeneous environment? (Multi-platforms create a multi-faceted situation for system administrators.)
How will we develop human interfaces that eliminate complexity and enable users to interact naturally with IT systems? (The final result needs to be crystal clear to the user.)
How can we bring together a group of autonomic components into a federated system? (Just creating autonomic components is insufficient.)
How can we design and support open standards that will perform? (Standardisation is critical as the era of proprietary solutions has ended.)
How can we produce adaptive algorithms to take past system knowledge and use those insights to perk up the rules? (Creative and new methods will be required to equip our systems to tackle the dynamic nature of environments and transactions.)
Research related to development of autonomic systems is indeed complex and challenging. However, future computer systems will need higher levels of automation if these are anticipated to manage the rapidly-increasing amounts of data, the ever-growing network and the rising force of processing power. While there are computers with various levels of automation, fully-autonomic systems remain a dream for the future.