This article discusses six broad stages of artificial intelligence (AI) solution lifecycle. New age AI solutions can be highly potent and may result in scalable damage when something goes wrong.

Acme Solutions (a hypothetical company) is experiencing significant growth in its products and services. Acme’s customer base is continuously increasing. An increase in the customer base is leading to an increased number of calls to their incident management support centre.

To keep up with the growth, Acme Solutions does not want to increase the headcount in their incident management support centre by implementing an artificial intelligent (AI) chatbot solution. By doing this, they expect to provide adequate support to incidents reported by customers, without additional headcount. Customers will be able to interact with chatbot and report their problems to, perhaps, get instant solutions too.
Should Acme Solutions embark on an AI chatbot project? If this project is completed, will it solve Acme’s problem(s)?
If you think deeply, you will realise a flaw in Acme’s thought process—their hypothesis. Their hypothesis is, if we implement an AI chatbot, we can address the increased number of customer reported incidents without the increased headcount.
What is wrong here?
The very first problem here is ‘retrofit thinking.’ Acme Solutions is starting with a solution in mind and then trying to fit in with their current issue of growing customer base and incident reports. They formed their hypothesis while already choosing the solution, which is the fundamental mistake in hypothesis framing.
Instead, if they focus on the problem first, the solution may be different. If Acme acknowledges that an increase in customer base is leading to increased incident reports, there is a fundamental flaw in their service or product. There is something inherent in their service or product that is causing incidents in the first place, and the best way to address it is to eliminate the cause of incidents.
Once Acme realises that solving flaws in product/service would eliminate or reduce the number of reported incidents, their need for increased headcount is likely to go away. When that happens, the need for AI chatbot will go away too.
In this case, if Acme were to go ahead with an AI chatbot, their incident count will not reduce. However, they will be able to respond to more customers that are reporting incidents. Now, no matter how intelligent and efficient this chatbot is, once customers start to report an incident, it means that they are already unhappy and frustrated with Acme’s product and service. Acme’s brand loyalty has already taken a hit. Solving customer problems would not restore it; at best, it will stop it from getting worse.
You will notice that AI risks do not necessarily start with the AI system or application itself. These risks would have already crept in, well before the solution building starts or deployment begins.
Therefore correctly framing the hypothesis, validating it with the data, and supporting it with statistical analysis is highly essential. It should be your very first checkpoint in evaluating the risks of the AI solution.
Let us use the accompanying figure, which shows six broad stages of the AI solution lifecycle. Using this as a reference to ask seven key questions will ensure your AI solution’s success.
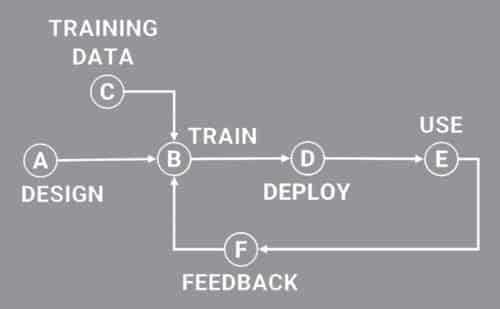
1. Are you addressing the right root cause?
Once you frame the correct hypothesis and validate that you indeed need an AI system to fix something for you, it is time to decide what exactly needs fixing?
Typically, we can establish a relationship between the problem and its cause in the following manner:
y=f(x)
where y is the problem and x is the cause or driver (or multiple causes or drivers) of that problem, and f represents the process or formula that makes x result in y.
If we continue with our earlier Acme Solutions’ example, it may look something like this:
Incident reports=f(poor product manual, low-quality product, etc)
It means incident reports are caused by poor product manuals, which customers cannot understand and therefore create an issue. It also means that sometimes the product manual may not be the only issue; poor product build may also cause an incident report.
So, if your solution was to address the increasing incident report problem, it cannot do anything to incident reports directly. It will have to work on the product manual, product build, and other contributing factors. When those factors are improved, incident reports will reduce automatically.
What if by implementing an AI-based transcriber, the product manual quality improves?
It would be a useful AI solution that is set to address a valid root cause. Your AI solution must be able to address one or more of the root causes of your main problem. It ensures that your issue will be solved.
If an AI solution is not addressing any of the root causes or is addressing only low-impact root causes, there is a risk, and you must fix it.
2. Is the solution correctly trained?
One of the critical stages in AI solution development is the training of the system.
If you are working with a sophisticated solution, it usually follows two-stage learning. In case of a simple AI solution, it happens in only one stage, that is, during the model building phase.
The training stage is where the foundation is formed for the first time, and the solution is trained using those models. Therefore the accuracy of these models is highly dependent on the training dataset.
If the data fed during the training of the solution is not good enough, it can result in several problems later on, and the risk would manifest in different forms.
For example, algorithmic bias may seep into the solution, which will affect all the outcomes. Machine learning (ML) algorithms identify patterns in the data and then build a predictive model based on that pattern. Any rule created or a decision taken by the AI solution is dependent on that. If those patterns have any bias in them, the solution will amplify that bias and may produce outcomes, which in turn may reinforce the bias further.
The risk with such invisible bias is that when the AI solution makes any errors, it is tough to diagnose and pinpoint the source of an issue.
If you suspect the training quality of your AI solution, or have doubts over the data used for training, the solution has a higher risk of problems. On the other hand, if you are confident about the source data and the training process followed, the risk is quite low.
There is not one and the absolute correct way to train the AI system; variations exist. If the confidence level in those training procedures and training data is low, the solution carries high-risk. Alternatively, if you are comfortable, it may be of low risk.

3. Has the solution considered all scenarios?
Following the premise of the solution that is designed right—one of the critical factors in evaluating the risks of the AI solution is the depth and breadth of design. You should understand and be confident that the solution at hand is fully equipped to handle the entire spectrum of scenarios that may occur in your business.
The AI systems do not perform their tasks consciously. These rely on the training data. It means that the system’s reliability and reliability of its outcomes are at risk if the input data had problems. These data problems are not just bias; they are also related to the representation of various scenarios in the data.
Typical IT solutions, including AI and alike, are mostly point-based. These focus on one goal with a handful of other parameters to optimise when achieving that goal. Unfortunately, these solutions can never be all-inclusive and holistic; it is too much to expect from them.
Let us take the example of an autonomous car. If you ask the car to take you to your destination as fast as possible, it may get you there. But, while getting there, you may have broken several traffic rules and put fellow traveller’s life at risk. None of this is acceptable. However, this may happen if your AI is too narrow and cannot see the forest of trees.
Many data with only a few types of scenarios cannot train the solution for real-life use cases, and this is a significant risk. Unless your training dataset represents all the possible use cases and scenarios, it is useless.
Since ML is an inductive process, the base model used by your solution can only cover what it has been trained on and seen in the data. If your training has missed low occurrence scenarios (also known as long-tail or edge cases), your solution will not be able to support them. Your solution will be too risky in those scenarios or may fail.
If the data is missing variety, it can lead to several problems in the future. The solution developed with a limited dataset and narrow training would be highly risky. Also, if the solution design has covered the breadth and depth of data and as many scenarios as reasonably possible, risks are lower.
4. Is there an option to stop gracefully?
A system that is designed right will always have an inbuilt redundancy. New-age AI solutions can be highly potent and may result in scalable damage when something goes wrong.
So, ask your development team, or your AI vendors, about the kill-switch. Check with them the possibility of stopping the system gracefully when needed.
A system without an option to stop gracefully is a highly risky system. You may not have an option to stop the system when needed. However, exercising this option is not as simple as pulling the plug. This means you may still face a significant risk of jeopardising business continuity in the process if you decide to stop it.
The ability to stop is not as bad as not being able to stop at all, though. In this case, you must evaluate your options and alternate plan. What are the financial and overall business repercussions of those alternative options when invoked? If stopping the AI system in an emergency would mean you are required to put up a hundred-member team in place to cope with the situation, it could be a significant financial and HR burden for you.
When evaluating your AI solution on this parameter, check the availability of kill switch or graceful-stop and restart options. If there are no such options, it is a high-risk solution.
However, if these options are available with some level of inconvenience and minor losses, it may be termed as a medium-risk solution. Although highly unlikely, there may be a solution that is easy to stop and restart. If it will not cost you too many resources, it may be a low-risk option and should be the most preferred one from a risk point of view.
If you cannot stop an AI solution easily and gracefully, it is a high-risk solution. On the contrary, if you are in full control and can exercise that option easily and without any significant loss, it is low risk, that is, a better solution.
5. Is the solution explainable and auditable?
A software solution, no matter how sophisticated, is always auditable, understandable, and explainable.
Specific to the AI solution, explainability has been one of the most talked-about topics. With so many different approaches to develop AI solutions, it is getting increasingly difficult to determine how systems are making decisions. With explainable and auditable AI solutions, we should be able to fix accountability, make corrections, and take corrective actions as well.
For many industries, AI explainability is a regulatory requirement. For example, with the General Data Protection Regulation (GDPR) laws in effect, companies will be required to provide consumers with an explanation for AI-based decisions.
There are growing risks of AI when implemented without adequate explainability. These risks affect ethics, business performance, regulation, and our ability to learn iteratively from AI implementations.
People do not want to accept arbitrary decisions made by some entity that they don’t understand. To be acceptable and trustworthy, you would want to know why the system is making a specific decision.
In addition to explainability, being auditable is another key to the right AI solution.
Whenever something goes wrong, you would need to recover an audit trail of the entire transaction. Without being auditable, AI solutions are a significant risk. In the absence of accurate records, regulatory fines may ramp up, and financial losses could pile up quickly.
Not only this, but it also becomes a limiting factor for you as a business. Without proper explanation and understanding, you cannot improve. Controlled and measurable improvements become near impossible when you are in the dark.
If the solution is explainable and auditable, the risk of wrong decisions and further ramifications is lower. It is better for improvements in the business.
6. Is the solution tailored for your use case?
Most of the AI solutions claim to be personalised for the end-users. However, the critical question is—before you deploy or start implementing those solutions—are these customised or tailored for you?
For many use cases, geography-specific rules apply. For example, if you are a European business, your obligations related to data handling and explainability, verifiability, etc, are different as compared to other countries. If your business is in China, facial recognition technology may be acceptable; however, for most of the other countries, it would be quite the opposite.
If you expect your solution to transcribe doctors’ notes and make prognosis or decisions based on that, your solution must understand local vernacular, slangs, and other language nuances. For example, trash can (US) versus garbage bin (AU), or sidewalk (US) versus footpath (AU), mean the same things but are different words. The examples given here are quite rudimentary. However, for a sophisticated application, language differences would mean a lot.
In case of a hiring solution or applicant tracking system (ATS), wouldn’t it be relevant if the solution was trained on localised or geography-specific data during the initial stage? The hiring pattern and criteria are significantly different for different countries, which means that the use of a standard solution is not a good fit for the purpose.
Geographical differences influence user interactions with any software system, and so does the user experience. It can be best handled during the solution design phase if the development team has local experts on board. These experts can provide valuable insights and knowledge to make the solution more effective and adaptable to the use case by end-users.
Not having a tailored solution for your use case is not a deal-breaker in most cases. However, it is safer to assume that the relevance is essential, so think about it, and evaluate it.
If the solution is not tailored to your use case, you may be dealing with high latent risk. Evaluating the level of customisation can help in estimating potential risks.
7. Is the solution equipped to handle drift?
The problem of change in data over time and thereby affecting statically programmed (or assumed) relationships is a common occurrence for several other real-life scenarios of machine learning. The technical term, in the field of ML, for this scenario is ‘concept drift.’
Here the term concept refers to the unknown or hidden relationship between inputs and outputs. The change in data can occur due to various real-life scenarios, which can result in degraded performance of your AI solution.
If the solution is designed right, it would have accounted for such drift in the first place and therefore would be able to adapt to the changing scenarios. If that isn’t the case, either your solution would fail, or the performance will degrade. It may also mean lower accuracy, lower speed, high error margins, and other such issues.
However, remember that it is difficult to identify any scenario in which concept drift may occur, especially when you are training the model for the first time. So, instead of working on pre-deployment detection, your solution should safely assume that the drift will occur and accordingly have a provision to handle it.
If your solution is not capable of handling drifts, you will have to fix it eventually on an ongoing basis. It is a costly proposition as you keep spending money on constant fixes. The risk of tolerating poor performance for some time exists. This risk increases if the detection of drift is not apparent. If you, for some reason, could not detect the drift for a more extended period, it can be quite risky on several fronts. Thus, the detection of drift is a critical factor too.
Check if your solution has accounted for concept drift and if yes, then to what extent? The answer to that check would tell you the level of risk.
A thorough evaluation is a key
From an economic point of view, there is significant information asymmetry that has put AI solution creators in a more powerful position than its users.
It is being said that technology buyers are at a disadvantage when they know much less about the technology than sellers do. For the most part, decision-makers are generally not equipped to evaluate these systems.
The crux of the matter is, you cannot leave it to the AI developers, in-house or outside, to police themselves for mindful design and development.
It is natural for us to evolve and keep pushing the envelope. However, certain things cannot be undone. There is no undo option here. Therefore it is imperative that we either slow down or be overly cautious.
Since slowing down is a less likely acceptable option, being overly cautious is necessary. Being strict in the evaluation of risks and putting up strong governance are some of the critical steps you can take.
If your search engine shows irrelevant results or a movie streaming service suggests you flop movies, it still may be a minor nuisance. However, if the system is controlling a car, or a power grid, or a financial trading system, it better be right, as even minor glitches are unacceptable.
For you to be confident in your AI system, you must make sure that you are working on the right solution, and the solution is designed right.
Tactically, ‘doing things right’ is essential, while strategically, ‘doing the right things’ is critical. But, with a powerful technology like AI at hand, both are essential.
Anand Tamboli is a serial entrepreneur, speaker, award-winning published author and emerging technology thought leader